Python Drivers
This page provides details for getting started with YugabyteDB Psycopg2 Driver for connecting to YugabyteDB YSQL API.
Yugabyte Psycopg2 driver is a distributed python driver for YSQL built on the PostgreSQL psycopg2 driver. Although the upstream PostgreSQL psycopg2 driver works with YugabyteDB, the Yugabyte driver enhances YugabyteDB by eliminating the need for external load balancers.
-
It is cluster-aware, which eliminates the need for an external load balancer.
-
It is topology-aware, which is essential for geographically-distributed applications.
The driver uses servers that are part of a set of geo-locations specified by topology keys.
Load balancing
The Yugabyte Psycopg2 driver has the following load balancing features:
-
Uniform load balancing
In this mode, the driver makes the best effort to uniformly distribute the connections to each YugabyteDB server. For example, if a client application creates 100 connections to a YugabyteDB cluster consisting of 10 servers, then the driver creates 10 connections to each server. If the number of connections are not exactly divisible by the number of servers, then a few may have 1 less or 1 more connection than the others. This is the client view of the load, so the servers may not be well balanced if other client applications are not using the Yugabyte JDBC driver. -
Topology-aware load balancing
Because YugabyteDB clusters can have servers in different regions and availability zones, the YugabyteDB JDBC driver is topology-aware, and can be configured to create connections only on servers that are in specific regions and zones. This is useful for client applications that need to connect to the geographically nearest regions and availability zone for lower latency; the driver tries to uniformly load only those servers that belong to the specified regions and zone.
The Yugabyte Psycopg2 driver can be configured with pooling as well.
Quick Start
Learn how to establish a connection to YugabyteDB database and begin simple CRUD operations using the steps in Build an Application in the Quick Start section.
Download the Driver Dependency
Fundamentals
Learn how to perform the common tasks required for Java App Development using the PostgreSQL psycopg2 driver
Note
The driver requires YugabyteDB version 2.7.2.0 or higherLoad balancing connection properties
The following connection properties need to be added to enable load balancing:
- load_balance - enable cluster-aware load balancing by setting this property to
True; disabled by default. - topology_keys - provide comma-separated geo-location values to enable topology-aware load balancing. Geo-locations can be provided as
cloud.region.zone.
Use the driver
To use the driver, do the following:
-
Pass new connection properties for load balancing in the connection URL or in the dictionary.
To enable uniform load balancing across all servers, you set the
load-balanceproperty toTruein the URL, as per the following example:Connection String
conn = psycopg2.connect("dbname=database_name host=hostname port=port user=username password=password load_balance=true")Connection Dictionary
conn = psycopg2.connect(user = 'username', password='xxx', host = 'hostname', port = 'port', dbname = 'database_name', load_balance='True') -
To specify topology keys, you set the
topology_keysproperty to comma separated values, as per the following example:Connection String
conn = psycopg2.connect("dbname=database_name host=hostname port=port user=username password=password load_balance=true topology_keys=cloud1.region1.zone1,cloud2.region2.zone2")Connection Dictionary
conn = psycopg2.connect(user = 'username', password='xxx', host = 'hostname', port = 'port', dbname = 'database_name', load_balance='True', topology_keys='cloud1.region1.zone1,cloud2.region2.zone2') -
To configure a SimpleConnectionPool, specify load balance as follows:
yb_pool = psycopg2.pool.SimpleConnectionPool(1, 10, user="yugabyte", password="yugabyte", host="127.0.0.1", port="5433", database="yugabyte", load_balance="True") conn = yb_pool.getconn()
Try it out
This tutorial shows how to use the Yugabyte Psycopg2 Driver with YugabyteDB. You’ll start by creating a three-node cluster with a replication factor of 3. This tutorial uses the yb-ctl utility. Next, you’ll use Python shell terminal, to demonstrate the driver's load balancing features by running few python scripts.
Note
The driver requires YugabyteDB version 2.7.2.0 or higherInstall YugabyteDB and create a local Cluster
Create a universe with a 3-node RF-3 cluster with some fictitious geo-locations assigned. The placement values used are just tokens and have nothing to do with actual AWS cloud regions and zones.
$ cd <path-to-yugabytedb-installation>
./bin/yb-ctl create --rf 3 --placement_info "aws.us-west.us-west-2a,aws.us-west.us-west-2a,aws.us-west.us-west-2b"
Check Uniform load balancing
Log into your Python terminal and run the following script:
import psycopg2
conns = []
for i in range(30):
conn = psycopg2.connect(user = 'username', password='xxx', host = 'hostname', port = 'port', dbname = 'database_name', load_balance='True')
conns.append(conn)
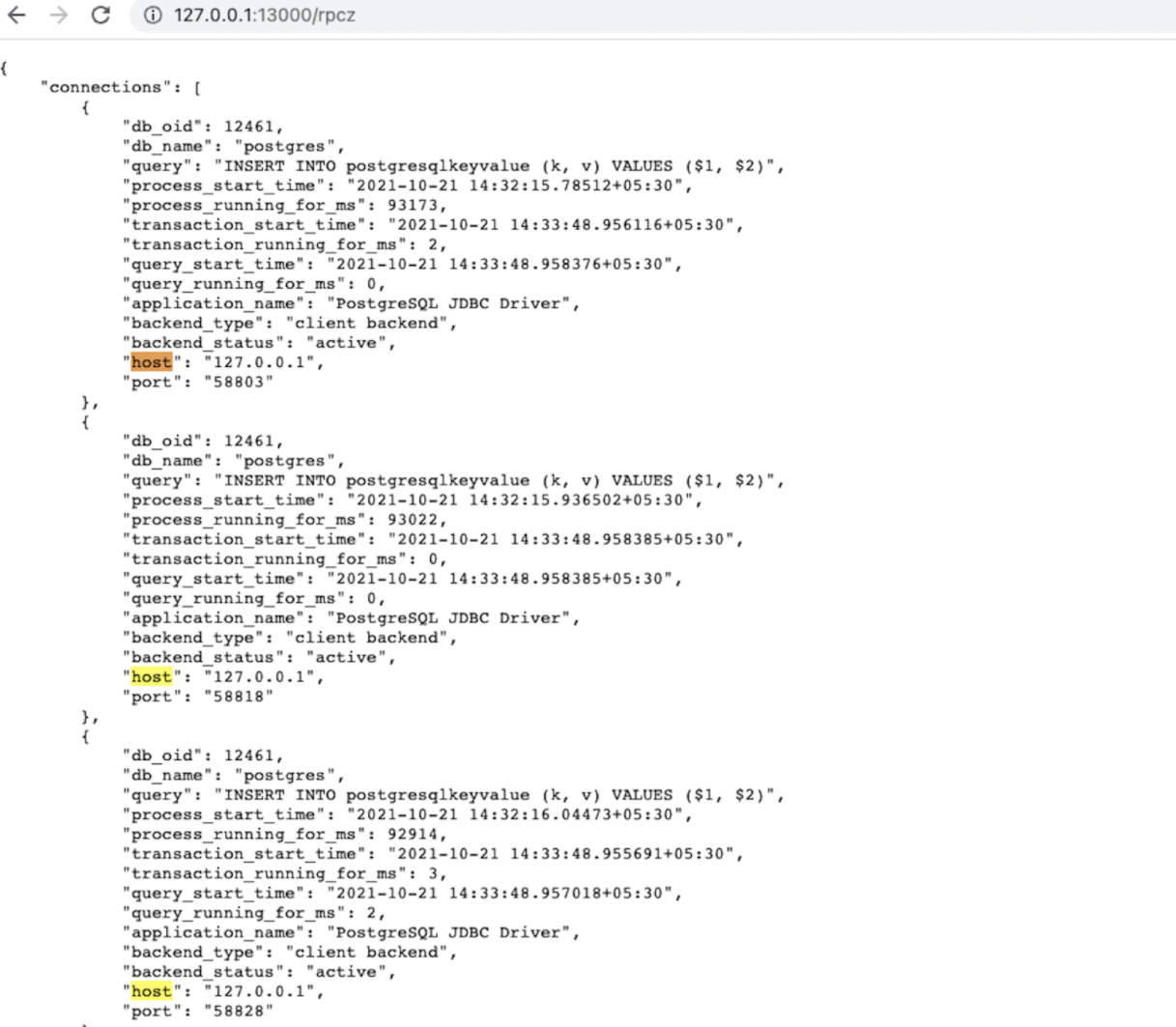
The application creates 30 connections. To verify the behavior, wait for the app to create connections and then visit http://<host>:13000/rpcz from your browser for each node to see that the connections are equally distributed among the nodes.
This URL presents a list of connections where each element of the list has some information about the connection as shown in the following screenshot. You can count the number of connections from that list, or simply search for the occurrence count of the host keyword on that webpage. Each node should have 10 connections.
You can also verify the number of connections by running the following script in the same terminal:
from psycopg2.policies import ClusterAwareLoadBalancer as lb
obj = lb()
obj.printHostToConnMap()
This displays a key value pair map where the keys are the host and the values are the number of connections on them (This is the client side perspective of the number of connections).
Check Topology-aware load balancing using yb-sample-apps
For topology-aware load balancing, run the following script in your new Python terminal with the topology_keys property set to aws.us-west.us-west-2a; only two nodes will be used in this case.
import psycopg2
conns = []
for i in range(30):
conn = psycopg2.connect(user = 'username', password='xxx', host = 'hostname', port = 'port', dbname = 'database_name', load_balance='True', topology_keys='aws.us-west.us-west-2a')
conns.append(conn)
To verify the behavior, wait for the app to create connections and then navigate to http://<host>:13000/rpcz. The first two nodes should have 15 connections each, and the third node should have zero connections.
You can verify this as well by running the previous verify script in the same terminal.
Clean up
When you're done experimenting, run the following command to destroy the local cluster:
./bin/yb-ctl destroy
Further Reading
To learn more about the driver, you can read the architecture documentation.